With some care, it turns out to be possible to spoof fake DNS responses using fragmented datagrams. While preparing a presentation for XS4ALL back in 2009, I found out how this could be done, but I never got round to formally publishing the technique. The presentation was however made available.
Update: this “discovery” has now been dated back to at least 2008 when Florian Weimer knew about it & tells us it was communicated clearly and widely back then.
In 2013, Amir Herzberg & Haya Shulman (while at Bar Ilan University) published a paper called Fragmentation Considered Poisonous. In this paper they explain how fragmented DNS responses can be used for cache poisoning. Later that year CZNIC presented about this paper and its techniques at RIPE 67.
A stunning 72 papers cite the original article, but as of 2018 not too many people know about this cache poisoning method.
More recently, The Register reported that another team, also involving Dr Shulman (now at Fraunhofer Institute for Secure Information Technology), has been able to use fragmented DNS responses to acquire certificates for domain names whose nameservers they do not control. They were able to demonstrate this in real life, which is a remarkable achievement. Incidentally, this team includes Amit Klein who in 2008 discovered & reported a weakness in PowerDNS.
Full details will be presented at the ACM Conference on Computer and Communications Security in Toronto, October 18. This presentation will also propose countermeasures.
Meanwhile, in this post, I hope to explain a (likely) part of their technique.
Whole datagram DNS spoofing
To match bona fide DNS responses to their corresponding queries, resolvers and operating system check:
- Name of the query
- Type of the query
- Source/destination address
- Destination port (16 bits)
- DNS transaction ID (16 bits)
The first three items can be predictable, the last two aren’t supposed to be. To spoof in a false response therefore means we need to guess 32 bits of random. To do so, the attacker needs to send the resolver lots and lots of fake answers with guesses for destination port and the transaction ID. Over (prolonged) time, their chosen response arrives ahead of the authentic response, is accepted, and they are able to spoof a domain name. Profit.
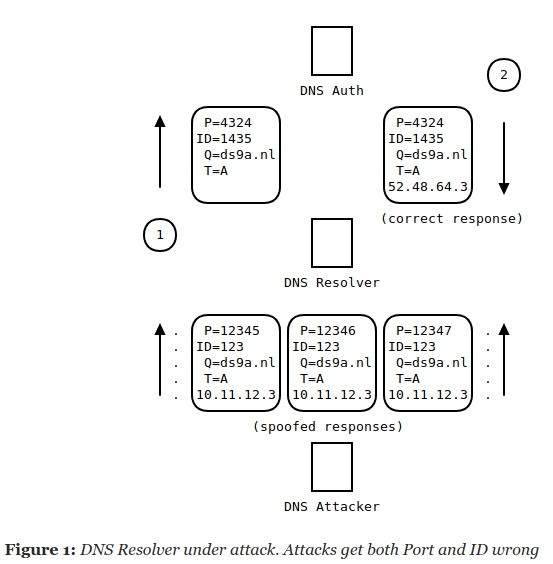
In practice this turns out to be very hard to do. The 32 bit requirement plus the short timeframe in which to send false responses means that as far as I know, this has been demonstrated in a lab setting just once. Anecdotal reports of blindly spoofing a fully randomized source port resolver have not been substantiated.
Fragments
DNS queries and responses can be carried in UDP datagrams. A UDP datagram can be many kilobytes in size – far larger than most UDP packets. This means that a sufficiently large UDP response datagram can get split up into multiple packets. These are then called fragments.
Such fragments travel the network separately, to be joined together again on receipt.
Fragmented DNS responses happen occasionally with DNSSEC, for example in this case:
$ dig -t mx isc.org @ams.sns-pb.isc.org +dnssec -4 +bufsize=16000
43.028963 IP 192.168.1.228.44751 > 199.6.1.30.53: 20903+ [1au] MX? isc.org. (48)
43.035379 IP 199.6.1.30.53 > 192.168.1.228.44751: 20903*- 3/5/21 MX mx.ams1.isc.org. 20, MX mx.pao1.isc.org. 10, RRSIG (1472)
43.035391 IP 199.6.1.30 > 192.168.1.228: ip-proto-17The final line represents a fragment, which only notes it is UDP (protocol 17).
Matching fragments together is quite comparable to matching DNS queries to responses. Every IP packet, even a fragment, carries a 16 bit number called an IPID. This IPID is not copied from the query to the response, it is picked by the DNS responder.
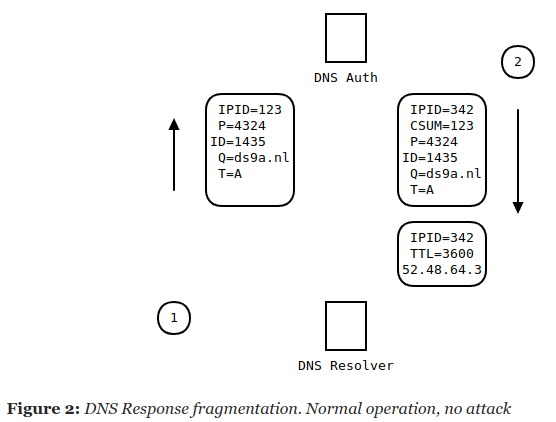
On receipt, fragments are grouped by IPID, after which the checksum of the reassembled datagram is checked. If correct, the DNS response gets forwarded to the resolver process.
If we want to spoof a DNS response, we could pick a DNS query that leads to a fragmented datagram, and then try to spoof only the second fragment. On first sight, this does not appear to be much easier as we now need to guess the IPID (16 bits) and we also need to make sure the checksum of the whole datagram matches (another 16 bits). This then also requires a 32 bit guess to succeed.
However, if we send a server a DNS query, it will most of the time send the same DNS response to everyone who asks (also for fragmented answers). In other words, if the attacker wants to spoof a certain response, it will know exactly what that response looks like – with the exception of the destination port and the DNS transaction ID (32 bits).
But note that both of these unpredictable parts are in the first fragment. The second fragment is completely static, except for the IPID. Now for the clever bit.
The ‘internet checksum’ is literally .. a sum. So the checksum of the entire datagram consists of the checksum of the first fragment plus the checksum of the second fragment (modulo 16 bits).
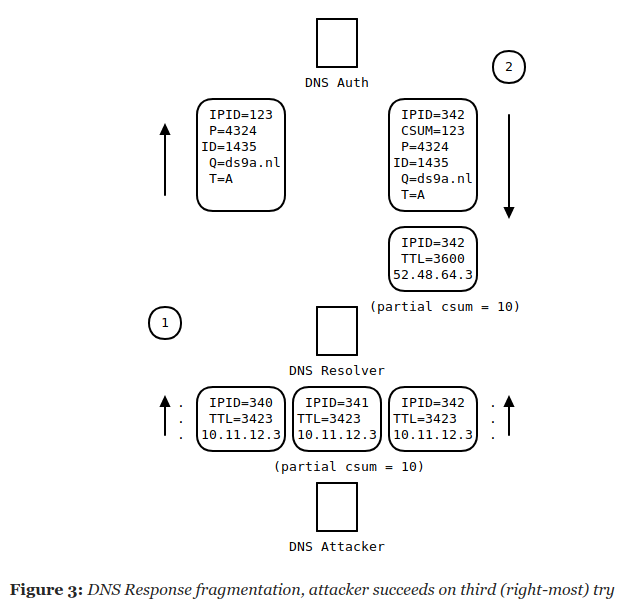
This means that to make sure the whole reassembled datagram passes the checksum test, all we have to do is make sure that our fake second fragment has the same known partial checksum as the original. We can pick the checksum of our fake second segment easily through the TTL of the our chosen response record.
This leaves us with only 16 bits to guess, which given the birthday paradox is not that hard.
Randomness of the IPID
So how random is the IPID, does it even represent a 16-bit challenge? According to the 2013 paper, some operating systems pick the IPID from a global counter. This means an attacker can learn the currently used IPID and predict the one used for the next response with pretty good accuracy.
Other operating systems use an IPID that increments per destination which means we can’t remotely guess the IPID. It turns out however that through clever use of multiple fragments, this still allows an attacker to “capture” one of these. See the original paper for details.
Is that it?
Definitely not. In order to get a certificate issued falsely using this technique requires several additional elements. First we must be able to force many questions. Secondly, we must make sure that the original authoritative server fragments the answer just right. There are ways to do both, but they are not easy.
I await the presentation at the ACM conference in October eagerly – but I’m pretty sure it will build on the technique outlined above.
Countermeasures
In the meantime, DNSSEC does actually protect against this vulnerability, but it does require that your domain is signed and that your CA validates. This may not yet be the case.
