In which I spend a lot of time proving a platform difference is not actually a platform difference, and eventually end up proven wrong.
PowerDNS make check/testrunner output on Debian 7.0/s390x:
test-dnsrecords_cc.cc(199): error in "test_record_types": Failed to verify TXT: Unable to parse DNS TXT '"ÅLAND ISLANDS"'
We don’t observe this failure on other systems, suggesting this is an s390x-specific issue. I find this very unlikely, so I’m trying to figure out what environmental difference is causing this. So far, I have come up short (but keep reading).
There are clues, of course. The output of ragel dnslabeltext.rl is different on s390x. Diffing the output directly did not yield anything useful for me, but Ragel has a graphviz output mode (-V), and diffing a (sorted) version of that output does help:
$ diff -u <(sort amd64.dot) <(sort s390x.dot)
--- /dev/fd/63 2013-10-24 18:19:41.000000000 +0200
+++ /dev/fd/62 2013-10-24 18:19:41.000000000 +0200
@@ -1,12 +1,12 @@
1 -> 2 [ label = "34 / segmentBegin" ];
- 2 -> 2 [ label = "DEF / reportPlain" ];
+ 2 -> 2 [ label = "-128..33, 35..91, 93..127 / reportPlain" ];
2 -> 3 [ label = "92" ];
2 -> 7 [ label = "34" ];
3 -> 2 [ label = "DEF / reportEscaped" ];
3 -> 4 [ label = "48..57 / reportEscapedNumber" ];
4 -> 5 [ label = "48..57 / reportEscapedNumber" ];
5 -> 6 [ label = "48..57 / reportEscapedNumber" ];
- 6 -> 2 [ label = "DEF / doneEscapedNumber, reportPlain" ];
+ 6 -> 2 [ label = "-128..33, 35..91, 93..127 / doneEscapedNumber, reportPlain" ];
6 -> 3 [ label = "92 / doneEscapedNumber" ];
6 -> 7 [ label = "34 / doneEscapedNumber" ];
7 -> 2 [ label = "34 / segmentEnd, segmentBegin" ];
In short, on s390x, instead of the DEFault transition, a limited set is used.
The relevant bits of Ragel input:
escaped = '\\' (([^0-9]@reportEscaped) | ([0-9]{3}$reportEscapedNumber%doneEscapedNumber));
plain = ((extend-'\\'-'"')|'\n'|'\t') $ reportPlain;
txtElement = escaped | plain;
main := (('"' txtElement* '"' space?) >segmentBegin %segmentEnd)+;
The whole graphviz plot is too wide to include here, so I’ll show some snippets with explanation:
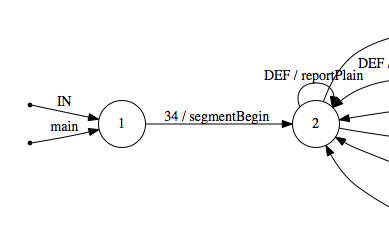
Parsing starts in state 1. From there, we demand 34 (the ASCII code for a double quote “) to go into state 2.
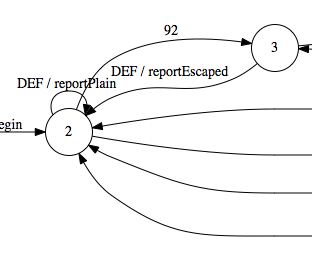
In state 2, there are a few options:
- We see 92 (a backslash), and we go into state 3 to handle an escaped character.
- We see something else. We pick the character up and drop right back into state 2.
- We get (unescaped!) 34 (“) and go into state 7 (EOF / segmentEnd) (not shown).
States 3-6 deal with escaped characters; there does not appear to be an issue there.
Where the pictures say DEF / reportPlain, on s390x instead we get a set of ranges (-128..33, 35..91, 93..127), which comes down to `everything from -128 to 127 inclusive, except for 34 and 92′. At first glance, this seems equivalent to the amd64 version, which says ’34 and 92 are special, the rest is not’. But obviously this is not true — the parser is rejecting our non-ASCII input on s390x.
From the Ragel docs:
extend: Ascii extended characters. This is the range -128..127 for signed alphabets and the range 0..255 for unsigned alphabets.
In other words, extend should cover the full 8-bit range. Then why is Ragel on s390x refusing to cooperate? Could the signed/unsigned difference be a clue?
No: as a test, I added -'x' to the definition of plain (on amd64), thus changing the parser such that no longer all of ASCII is covered:
plain = ((extend-'\\'-'"'-'x')|'\n'|'\t') $ reportPlain;
If I do this, DEF turns into -128..33, 35..91, 93..119, 121..127 — similar to the s390x version, with one more character (the ASCII code for x is 120) excluded, of course. With this change, the tests still pass (except for one that actually contains an x).
This means that on both platforms, Ragel considers our character set to be signed. Yet, on s390x it is rejecting our non-ASCII characters (that would, as far as I can see, be covered under -128..0).
In a test on amd64, I can see that the two bytes in Å (UTF-8), 0xc3 0x85, are mapped as -61 and -123 respectively, matching our understanding that Ragel considers our characters to be signed.
HOWEVER, if I stick the same character/bytes into dnslabeltext.rl on s390x, I see that they are mapped to 133 and 195. This means that although Ragel is generating a parser for signed characters on both platforms, it is considering the input to be unsigned on s390x.
Debian has kindly provided a table of how various types operate on different architectures. Indeed, this shows that char is unsigned on s390x but signed on amd64.
While trying to find more information on the signed/unsigned distinction in Ragel, I ran into the doc section about alphtype, which allows one to specify the type of the parsed alphabet. Setting it to signed is not allowed (!), suggesting that Ragel was never meant to cope with signed char alphabets. Setting it to unsigned on s390x fixed my issue, without breaking anything on amd64.
Workaround now in our source tree.
For me, this closes the case. I emailed ragel-users but no definitive reply has come in.